

In the ever-evolving landscape of data engineering, the Data Mesh concept has emerged as a transformative paradigm for managing and utilizing data. With the exponential growth of data and the increasing complexity of data systems, traditional monolithic architectures like data warehouses and centralized data lakes are often proving inadequate. Data Mesh offers a decentralized and domain-driven alternative, enabling organizations to scale their data operations effectively while empowering teams to own and manage their data independently.
In this blog, we’ll explore what Data Mesh is, its core principles, how it compares to traditional architectures, and its potential benefits and challenges.
What Is Data Mesh?
Data Mesh is a decentralized data architecture introduced by Zhamak Dehghani. Unlike traditional monolithic systems, where data is centrally owned and managed, Data Mesh decentralizes data ownership to domain-specific teams. Each domain team treats data as a product, ensuring that the data they produce is discoverable, reliable, and usable by others in the organization.
This approach aligns with the principles of domain-driven design (DDD), enabling teams to focus on the data most relevant to their business context while maintaining interoperability across the organization.
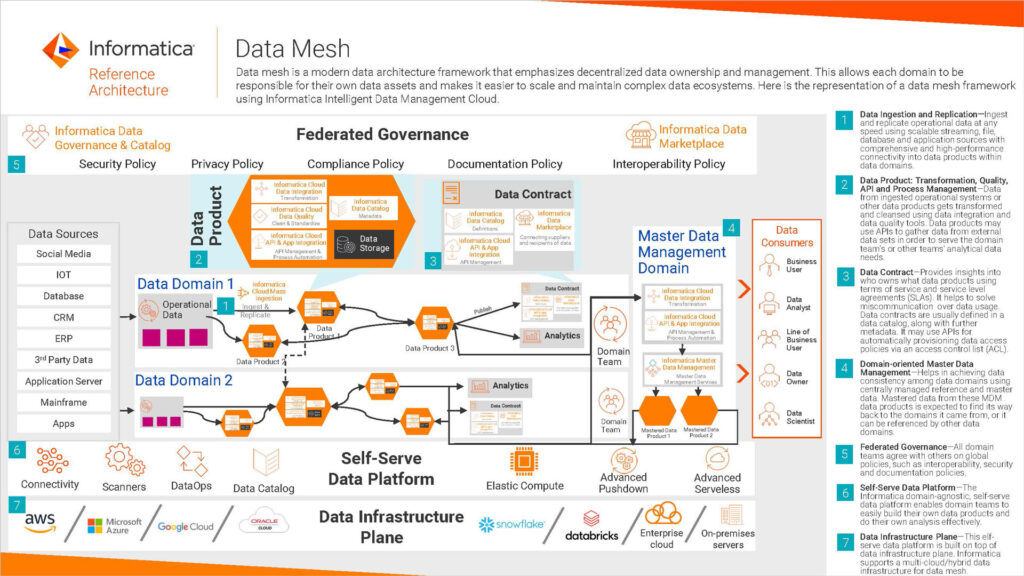
Core Principles of Data Mesh
Data Mesh is built on four foundational principles:
1. Domain-Oriented Data Ownership
In a Data Mesh architecture, data ownership is distributed across the organization, with each domain team responsible for the data it produces. For example, a marketing team may own customer engagement data, while a finance team owns transaction data. This model fosters accountability and ensures that data is maintained by those with the deepest domain knowledge.
2. Data as a Product
In a Data Mesh, data is treated as a product, much like software. This means domain teams must prioritize user experience, reliability, and quality when producing and sharing their data. Data products should have well-defined APIs, clear documentation, and mechanisms for feedback to meet the needs of their “customers.”
3. Self-Serve Data Infrastructure
To support decentralized data ownership, organizations need to provide a self-serve data infrastructure. This infrastructure abstracts away the complexities of managing data pipelines, storage, and security, allowing domain teams to focus on their core responsibilities without requiring deep technical expertise in data engineering.
4. Federated Computational Governance
Decentralization doesn’t mean chaos. Federated governance ensures that data across the organization adheres to common standards and policies, such as security protocols, data privacy regulations, and interoperability requirements. This governance is achieved through collaboration between domain teams and a central governing body.
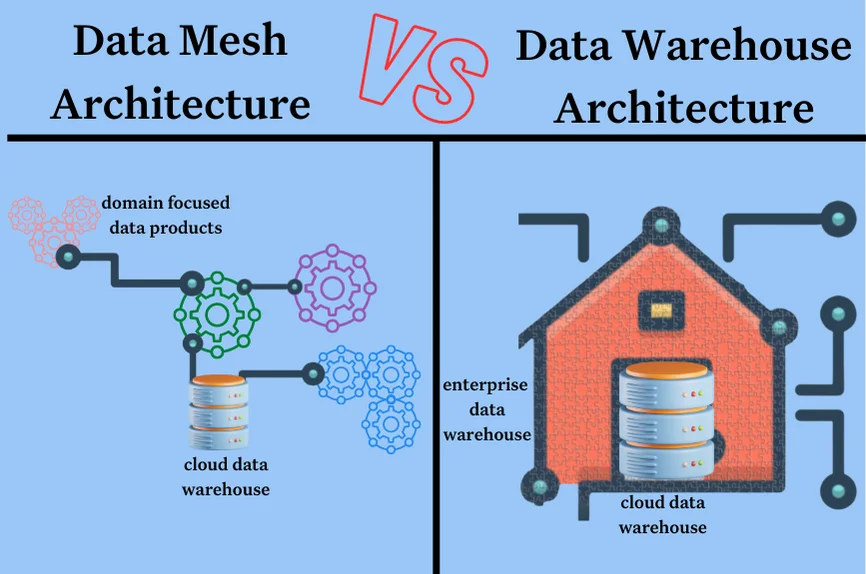
Data Mesh vs. Traditional Architectures
| Feature | Traditional Architecture | Data Mesh |
|---|---|---|
| Ownership | Centralized (data teams) | Decentralized (domain teams) |
| Scalability | Limited by central bottlenecks | Scales with domains |
| Focus | Technology-driven | Domain-driven |
| Flexibility | Rigid, hard to adapt | Agile, supports innovation |
| Governance | Top-down | Federated |
Traditional architectures like data lakes often struggle with bottlenecks caused by centralized teams, leading to slower time-to-insight and reduced flexibility. In contrast, Data Mesh allows organizations to adapt quickly to changing business needs.
Benefits of Data Mesh
- Scalability Decentralized ownership allows organizations to scale their data operations more effectively by removing bottlenecks caused by centralized teams.
- Improved Data Quality With domain teams treating data as a product, there’s a stronger emphasis on quality, reliability, and usability.
- Faster Time-to-Insight Domain teams can iterate faster, delivering insights and innovations without waiting for centralized approvals or resources.
- Empowered Teams Data Mesh promotes autonomy and accountability, enabling teams to make data-driven decisions independently.
- Enhanced Collaboration By creating discoverable and interoperable data products, organizations can foster collaboration between teams.
Challenges and Considerations
- Cultural Shift Adopting a Data Mesh requires a significant cultural change, as teams must embrace new responsibilities and ways of working.
- Complexity in Governance Federated governance requires careful planning and collaboration to avoid fragmentation and ensure compliance with organizational policies.
- Infrastructure Readiness Organizations must invest in self-serve data infrastructure to support decentralized teams effectively.
- Skill Gaps Teams may need training to manage and produce data products, especially if they lack technical expertise.
- Initial Investment Setting up a Data Mesh architecture involves upfront costs and effort, which may be a barrier for smaller organizations.
Best Practices for Implementing Data Mesh
- Start Small Begin with a few pilot domains to test and refine your approach before scaling across the organization.
- Invest in Infrastructure Build robust self-serve tools and platforms to empower domain teams and reduce technical barriers.
- Foster Collaboration Encourage communication and collaboration between domain teams and the central governance body to ensure alignment.
- Measure Success Define clear metrics for success, such as improved data quality, faster insights, or increased user satisfaction.
- Promote a Product Mindset Train teams to think of data as a product, emphasizing usability, reliability, and customer satisfaction.
Real-World Applications
Several organizations have successfully adopted Data Mesh principles to transform their data ecosystems:
- Netflix: Uses a domain-oriented approach to manage its vast data ecosystem, enabling rapid insights and innovations.
- Shopify: Treats data as a product, fostering collaboration between teams and improving data accessibility.
- Zalando: Implemented a federated governance model to align data operations with its domain-driven organizational structure.
These examples demonstrate the potential of Data Mesh to address the challenges of modern data architecture while unlocking new opportunities for growth and innovation.
Conclusion
Data Mesh represents a fundamental shift in how organizations think about and manage data. By decentralizing ownership, treating data as a product, and enabling self-serve infrastructure, Data Mesh empowers teams to innovate and scale effectively. While the journey to adopting this architecture may be challenging, the benefits of improved data quality, faster insights, and enhanced collaboration make it a compelling choice for modern enterprises.
As data continues to grow in importance, organizations that embrace concepts like Data Mesh will be better positioned to leverage their data as a strategic asset. Whether you’re just starting your data engineering journey or looking to transform your existing architecture, exploring Data Mesh principles could be the key to unlocking the full potential of your data ecosystem.
What’s your take on Data Mesh? Share your thoughts in the comments below!



